web synth docs
glowtts
Website: https://edresson.github.io/SC-GlowTTS/, internet archive: https://web.archive.org/web/20210603044213/https://edresson.github.io/SC-GlowTTS/
Research paper: https://arxiv.org/abs/2104.05557
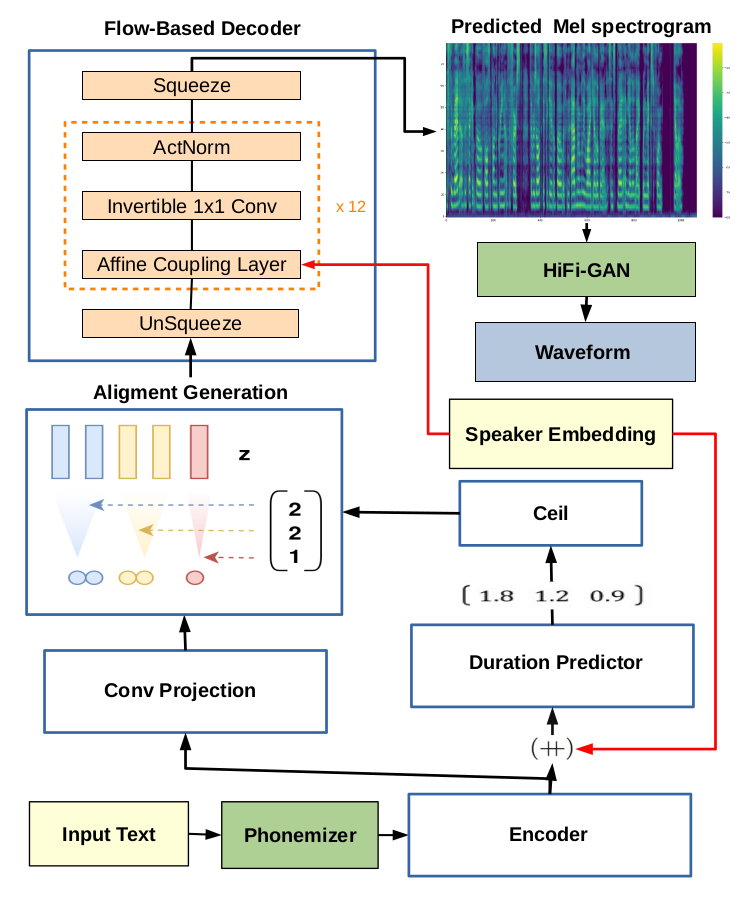
GlowTTS is a modern (research paper released April 2021) [tts] model. It has a unique architecture that allows for very fast [vocal-synthesis] and "an order-of-magnitude speed-up over the autoregressive model, [tacotron-2]. It's a machine learning-based approach and uses [GAN]s and [mel-spectrogram]s along with several other components in a rather complicated architecture to generate output waveforms.
"Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers." (from website)
It's definitely state-of-the art stuff; compared to a lot of similar projects that I've seen, everything seems to be very well put together and packaged. It is used as the underlying [vocal-synthesis] engine of the [larynx] [tts] engine, and the results are impressive considering how easy it was to set up and how quickly the output speech is synthesized.
Architecture Diagram: